

An Undocumented Bit of GREP Gold
I was recently posed with a GREP challenge from a colleague that I thought would be relatively easy to solve in a dedicated GREP-savvy text editor like BBEdit, but it required something I wasn’t quite sure InDesign’s GREP Find/Change would handle.
The problem was this: removing duplicate lines in document of company listings. In this particular case, it was 10,000 companies, so doing it manually was not an option. In each listing, there was a company name and address. In some, the first line of the listing was duplicated on the second line, but not all listings had this problem. The challenge was to use GREP to determine which were the problem listings, fix them, but leave the other listings as they were.
Here’s an example of a correct listing:
Company Name
Street Address
City, State, Zip
and this is how the problem listings showed up:
Company Name
Company Name
Street Address
City, State, Zip
If I were to go by the book, and didn’t know about GREP before it became part of InDesign, I probably would’ve thrown my hands up and said it couldn’t be done. However, once again, testing something out “just to see” if it would work paid off surprisingly well.
When I do GREP searches, I try to frame in my mind the “idea” of the search as clearly as possible. What is it I’m looking for, exactly? In this case, I was looking for a line of text that is followed by another line made up of exactly the same text.
Since using literal text is out of the question (each of the 10,000 listings is different), I needed a way to refer back to one part of the search criteria. This “backreference” is, in InDesign, typically only done in the “change to” part of the search, using the “Found Text” metacharacters ($0, $1, $2, and so on). However, those metacharacters don’t appear in the special characters for search menu at the end of the Find what field, nor do they work if you just type them in.
But I remembered that in BBEdit, you can do backreferences within a search. For instance, to look for the common duplicate word typo “the the,” you can search for (?‹=\1 )(the), which uses Positive Lookbehind to search for a subexpression consisting of the word “the,” but only if it is preceded by that same word and a space.
In BBEdit, the \1 metacharacter is the equivalent of InDesign’s $1 metacharacter for “Found Text 1,” and while that BBEdit convention would not be honored in the Change to field, I decided to give it a shot in the Find what field…and, sure enough, it works! This is completely undocumented GREP support that is very important. Without it, this text cleanup task would be impossible.
So…to extend this out to solve the duplicate line problem, I needed to define a line (any string of text followed by a return) as a subexpression (by enclosing it in parentheses), then use a backreference to define a duplicate of that same line, using BBEdit’s “found text 1” metacharacter (\1) instead of InDesign’s ($1).
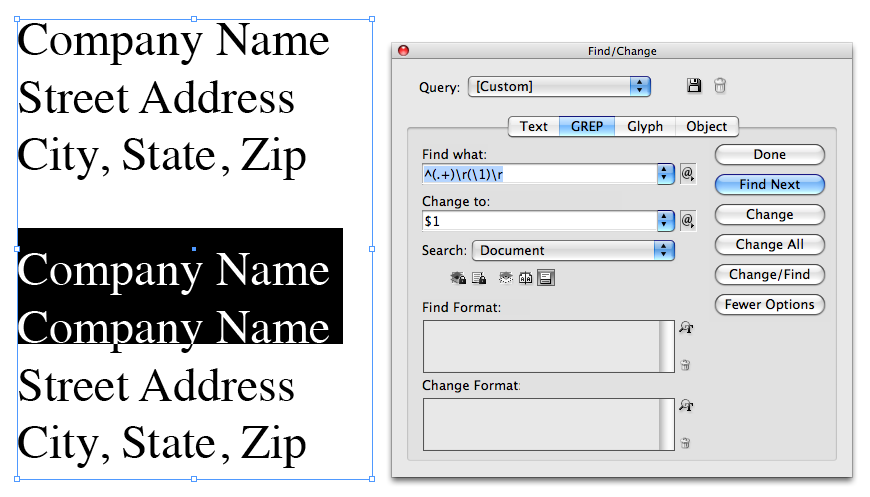
So, in the Find what field, the search string appears this way:
^(.+)\r(\1)
^ defines the beginning of a line
(.+) is a subexpression made up of any character one or more times
\r is a paragraph return
(\1) refers back to whatever text was matched by (.+) above.
In the Change to field, I only want to put back one of these two instances. However, I’ve created two subexpressions. The first is (.+), which InDesign would consider Found Text 1 ($1), and the second is the backreference (\1), which InDesign would consider Found Text 2 ($2). In this instance, it doesn’t really matter which of the two I put back, since they’re both the same, so I opted to put back the first one. To do that, all I needed to do was put $1 in the Change to field.
In my opinion, as a GREP geek, this is a huge hidden functionality discovery that opens up even more possibilities for an already great InDesign feature. The screen shot below shows this in InDesign’s Find/Change dialog, along with what it finds on the page.
You can follow any responses to this entry through the RSS 2.0 feed. Both comments and pings are currently closed.
February 3rd, 2009 at 4:14 am
Hi Michael,
Good to see you back posting 🙂 Yes GREP is an incalculable mystery and it’s probably one of the best features introduced to InDesign. The tip is magnificen, as you say, it’s completely undocumented.
There is one thing though, I don’t think that GREP find and replace works if there is a space at the end of the sentence? It might be an idea to run a search to clean up the text first. Something like this:
(.+)\s$
Then run the posted search then I think all would be well 🙂
I have to admit, I didn’t know about the trick that is posted, it is truly wonderful and I’ll never forget it.
Thanks
February 3rd, 2009 at 4:22 am
Sorry –
(.)(\s+)$
actually that works better for finding and removing spaces from the end of a paragraph – just replace with $1
February 3rd, 2009 at 3:10 pm
Interesting… I love using GREP in InDesign and think that a useful InDesign feature would be the ability to run multiple GREP presets on a given document to automate more complex FIND/CHANGE or GREP searches.
Meanwhile, as an Apple/Java script newbie, I was wondering if anyone knew how to accomplish this task and even provide a sample script to run multiple GREP presets on a given document in InDesign.
February 3rd, 2009 at 3:39 pm
Eugene —
The any character metacharacter (.) will also find spaces at the end of a line. It finds any kind of character, except a hard return. However, your post brings up a good point. If the first line in this example contains just the company name, but the second line contains the company name followed by a space, this GREP query will not consider it an exact match, so it will be passed over.
However, I was just trying to get across how this bit of hidden magic can be used. Every GREP cleanup task will have its own unique obstacles to overcome.
February 3rd, 2009 at 3:43 pm
Eugene —
A simpler GREP expression for finding all trailing spaces at the end of a line is:
\s+$
Just leave the Change to field blank to remove all of those spaces.
February 3rd, 2009 at 3:58 pm
@ Michael D —
The Find Change by List script (Window > Automation > Scripts) that ships free with InDesign does exactly that. You can create a successive series of Find/Change operations (which can include text and GREP searches) that will be run one after another when you double-click the script name. It requires a bit of set-up time, and custom configuration of the FindChangeList.txt file (Adobe InDesign CS4 > Scripts > Scripts Panel > Samples > JavaScript > FindChangeSupport), but once that’s done, you can use the script to run all of your standard text cleanup queries.
David and Anne-Marie talk about it in Episode 90 of InDesign Secrets, and there’s an article covering it in Issue #26 of InDesign Magazine
February 3rd, 2009 at 5:32 pm
Hi Michael, apologies if it appeared I was taking away from the excellent tip. However, when I tested it I discovered it wasn’t working because there were spaces, so just thought I’d point it out for others using the GREP and not getting matches.
And I love simpler greps, it’s been a while since I used GREP and of course I’m starting to forget some it 🙁
It is a fantastic tip, and I’m going to have to find me some work that requires some GREPing, as it’s fantastic stuff to know. I urge anyone to learn it and use it and be comfortable with it.
If the original post didn’t wet your lips then I don’t know what will. 🙂
February 3rd, 2009 at 10:28 pm
Hi Michael,
Another great GREP tip. Thank You!
JW
February 5th, 2009 at 5:12 pm
Bonjour à tous,
Je réponds en français à Michael D au sujet de “I was wondering if anyone knew how to accomplish this task and even provide a sample script to run multiple GREP presets on a given document in InDesign”. Peter Kahrel, dans Grep in InDesign CS3/CS4, p. 42 (oreilly.com) donne la solution pour utiliser plusieurs regex :
app.loadFindChangeQuery (“query_1”, SearchModes.grepSearch);
app.activeDocument.changeGrep();
app.loadFindChangeQuery (“query_2”, SearchModes.grepSearch);
app.activeDocument.changeGrep();
query_1 et query_2 sont les noms de l’expression régulière enregistrée dans le paneau “Rechercher/Remplacer”, onglet “GREP”.
Je vous invite à lire cet indispensable Short cut.
LT
February 12th, 2009 at 1:17 pm
Michael,
For the record, \1 is pretty well documented. It’s part of standard GREP implementations, see e.g. Friedl’s “Mastering Regular Expressions” (O’Reilly 2006) and http://www.regular-expressions.info/brackets.html.
In the context of InDesign it was documented in http://oreilly.com/catalog/9780596517069/index.html. That title (from 2007) alse has an example that shows how to remove duplicate lines (p. 27).
Regards,
Peter
February 12th, 2009 at 1:27 pm
Hi, Peter —
Thanks for the contribution. Also for the record, when I say “undocumented,” I always mean undocumented by Adobe (not in the help files or the User Guide). Their metacharacter table in the online and PDF help make no mention of support for these established GREP conventions, along with a few other important, but missing, gems like the “end of story” metacharacter (\Z), among others.
March 6th, 2009 at 2:51 pm
Hello!
I’m excited to have stumbled across your blog/podcast in a search for information about GREP and its functions. Been reading furiously trying to solve a find/replace problem I’m having. Perhaps this has already been addressed, but I cannot seem to find a reference!
I need to reformat text direct from a copyeditor (who used Word); they’ve used characters instead of formatting (i.e., Name: to indicate the word “Name:” should be italicized). I can’t seem to figure out how to tell InDesign to find text within the character designations and . Once that’s figured out, I just need to replace with the appropriate format.
There is probably a pretty simple solution; my understand of GREP just hasn’t stretched this far yet! I’d appreciate any guidance!
March 6th, 2009 at 2:54 pm
hmm… the comment I just posted erased the formatting to which I was referring. That’s part of the problem, I guess. It wants to be read as a code and I want it to be searched for as characters!
Perhaps this works? The characters (phrases?} are “” and “” without the spaces in between. In between those two phrases is a word that needs to be formatted.
Eek. Sorry about the confusion.
March 6th, 2009 at 3:21 pm
Julianne —
GREP can, indeed make short work of this task. However, I am literally writing the last few pages of the very last chapter of my book (which, by the way, includes a lot of great GREP info) and must plow through ’til it’s done. I will post a response for you once that’s off my plate.
March 13th, 2009 at 1:35 am
I really appreciate the information provided on the site. I found a solution to my problems regarding the GREP. Thanks for contributing in my work.
March 17th, 2009 at 2:28 pm
Julianne,
I noticed your post and just happen to be viewing Adventures in GREP for InDesign CS4 by Mike Witherell. I believe he answers your question in the Useful GREP search examples section, find “quoted words” and change to italic. The following should work:
Find: (~{)(\u*\l*\s*.*\w*\d*)(~})
Replace: $2 and italic character style formatting
Note: This finds the quotes but leaves them out since it only changes to found group 2; not 1 and 3.
Regards,
Greg
March 17th, 2009 at 3:14 pm
> I noticed your post and just happen to be viewing Adventures in GREP for InDesign CS4 by Mike Witherell. I believe he answers your question in the Useful GREP search examples section, find “quoted words†and change to italic. The following should work:
>Find: (~{)(\u*\l*\s*.*\w*\d*)(~})
Very complicated, why not use posive lookahead/behind?
(?<=”).*?(?=”)
March 17th, 2009 at 4:04 pm
That would be my recommendation, too.
Sorry for the slow reply, Julianne, but your best bet in this situation is to use Positive Lookbehind (to look before the word surrounded by the characters or lead-in information like “Name:”) and Positive Lookahead (to look after the text for the ending quote or other indicator left for you by the editor). So…if you were looking for “Name:Michael Murphy”, where “Michael Murphy” could be anyname, your search would be:
(?<="Name:)(.+?)(?=")What that translates to is “any one or more characters (shortest match), only if it’s preceded by “Name: and only if it’s followed by a quotation mark.
Hope that helps. If I’ve misinterpreted the particulars of how it’s sent to you, let me know and we can hammer out a bullet-proof solution together.
Michael
March 19th, 2009 at 2:47 pm
If you want some screen shots, I covered the “find between [whatever] and format it” issue a while back in this post:
http://indesignsecrets.com/findbetween-a-useful-grep-string.php
In my examples I didn’t want to delete any text (like “Name:”), just format part of it, so I left the Change field empty. But of course if you want to remove the label as well, then you’d use the $2 (etc.) method in the Change field.
April 28th, 2009 at 7:48 am
Challenge…!
Not sure this is possible, but it would save me a looot of work if so.
Got a table with phonenumbers all stuck together. 8 digits, no space.
Is it possible to divide these numbers in to 3 sections using GREP?
Norwegian mobilenumbers are all divided in to 3 2 3, while stationary phones are 2 by 2 (all of them 8 digits).
Do I make a fool out of my self hoping GREP could fix this?
Really hope for some good answers to this one… I absolutely hate going down this looooong list of numbers dividing them with space each every one!!!
Love your page!!! Extremely useful….
Anita (Westcoast of Norway)
April 28th, 2009 at 11:37 am
Anita — This is an easy one, depending on the answer to this question: how do you know which numbers are mobile and which are not if they’re all 8 digits with no spaces at the moment? GREP can easily find and change phone numbers for you, but if you need to treat some differently than others it’s slightly more involved.
June 22nd, 2009 at 1:31 pm
Hello,
Here is the challenge.
I have been using InDesign since it came out, and have great results.
However, I am brand new to GREP, and was wondering if a script could be made by me (a person who does not understand script), to do the following:
I have tons of copy, regularly, with a number of different ligatures in it. One (of the many, the fi ligature) causes the client to cringe. Is it possible to change this ligature by – turning off – the fi ligature only? Because I am out of the old school, I appreciate ligatures, and tight kerning.
I realize, I could just turn off ligatures, but, would rather not.
Thank you,
Lain Kennedy
June 22nd, 2009 at 2:13 pm
Lain —
You don’t need a script to do this. There’s a good way to do it in CS3 (with GREP Find/Change) and a better way to do it in CS4 (with a GREP Style).
The First Step: Create a Ligature-Killing Character Style
Whichever version you’re using, the beginning of the process is the same. Make a character style that has everything else about it shut off or undefined (in other words, every field for Font, Style, Size, etc. should be blank, all checkboxes left in the “neutral” state, and all pull-down menus set to Ignore (or completely blank). The only thing that should be assigned to this character style is that Ligatures should be specifically shut off (as shown below).
The CS3 Method:
In CS3, you can turn off the ligatures using this style with Find/Change, and it can be a Text-based Find/Change. There’s no GREP required for this in CS3. Simply do a case-sensitive search for the letters “fi” together. Leave the Change to field blank and from the Change Format settings, choose the character style created above to be applied to all instances of “fi” in your document (or story, or selection, or whatever range suits your needs). Find the first instance, then click Change All. That will apply the character style that disables ligatures to all instances of a lower-case “fi” pair in your text.
You’ll need to run this Find/Change operation whenever the document’s text is changed, just to be sure that new “fi” pairs haven’t been added to the text that don’t have this character style applied. The same would be true if you created a script to do this, as scripts need to be run each time you want to take advantage of their functionality.
The CS4 Method:
Find/Change is not necessary in CS4. Instead, create a new GREP Style within the paragraph style (or styles) where you want the “fi” ligature turned off. In the GREP Style options, select the character style created in the first step, and put “fi” (without the quotes) in the “To Text” field. The GREP Style eliminates the need to do multiple Find/Change operations, as it continuously scans the paragraph for “fi” combinations and automatically applies the character style to every one it finds.
Hope this helps,
Michael
June 24th, 2009 at 3:51 am
Hello again!
There are no spaces inbetween the numbers.
They’re like this:
57750444
57750455
57750555
And my problem is that I have to divide them to this:
57 75 04 44
57 75 04 55
57 75 05 55
Is this possible?
I’m lazy, therefore I love GREP!
June 24th, 2009 at 7:09 am
Anita —
This is a very easy one. You’ve got a pattern of 8 digita per line and you want to divide that into four sets of two digits each.
In the Find What field, the pattern is described as:
(\d\d)(\d\d)(\d\d)(\d\d)The parentheses around each of the two “any digit” metacharacters marks them as a sub-pattern to be remembered so you can refer back to it in the change part of the query.
Alternately, you can describe the pattern as:
(\d{2})(\d{2})(\d{2})(\d{2})They’re just two different ways of doing the same thing.
In the Change to field, you recall those four sub-patterns with Found Text metacharacters, referring to each of the four sub-patterns numerically, in the order in which they appear (1st, 2nd, 3rd and 4th, in this instance). In between each, you add a space (or two spaces, or however much you need).
That Change To pattern is described as:
$1 $2 $3 $4That puts back each pair of unique numbers found with space between each pair.
June 30th, 2009 at 1:14 am
Heeey! Thanks and thanks again!!!! You just saved my customer an hour of spacing!!!
September 1st, 2009 at 5:56 am
Another question…
Norway does not have the same quotationmarks as US. I’m struggling to find out how to do this…
I need to find:
” Any text with in quatationmark”
and turn it into
«found text but with norwegian marks»
This is probably dead easy… But I cant seem to figure it out.
Please help me once again!
Neets
September 1st, 2009 at 8:26 am
Hello again, Anita —
If you want to find any text within US quotation marks and change it to your Norwegian marks, you need to specify the quotation mark characters without using the options available under the Quotation marks sub-menu of the special characters flyout menu. The options there don’t distinguish between the two.
The most bullet-proof way of doing this is to refer to each specific quote type by its unicode value. In the Find What field, you would enter the following:
\x{201C}(.+?)\x{201D}That translates as “an opening left double quotation mark, followed by any character, one or more times (shortest match), followed by a closing right double quotation mark. The part of the expression that describes the text within those quotes is enclosed in a marking subexpression (within parentheses), so it can be put back later.
In the Change To field, you would enter the following:
\x{00AB}$1\x{00BB}That puts back the text that was within the quotation marks, but surrounds them instead with the proper double-angle quotation marks, left and right.
I tested this on my end and it works fine. Let me know if it solves your specific challenge.
Michael
September 4th, 2009 at 7:36 am
Sorry Michael!
“Cannot find match.” it says!
Per â€Elvis†Granberg (1941-1980) startet sin artistkarriere i musikalen â€South Pacific†i 1954. Hans rockekarriere skjøt for alvor fart i 1958 og han var aktiv fram til 60-tallet.
This is a typical text that we have to change all the quotation marks on…
And it can’t seem to find it… The text is copied from Word.
And I would like it to look like this;
Per «Elvis» Granberg (1941-1980) startet sin artistkarriere i musikalen «South Pacific» i 1954. Hans rockekarriere skjøt for alvor fart i 1958 og han var aktiv fram til 60-tallet.
As you can see, its a s***te job when the customers hit a quotation mark high! I have to change the dictionary to Norwegian: BokmÃ¥l, then the double quotes into «»…Then start the prosess using Find/Grep to change them all in to the left side «, and once more to change every other (right side ») using Find next -> Change -> Find next… Not funny at all…!
Thank you SO much for helping me out!
As you can see, it’s bloody frustrating to work like this… :o)
Anita
September 26th, 2009 at 7:24 am
Anita –
in case your problem w/ the replacement of quotation marks into norwegian quotation marks has not already been solved, here is my idea: Michael used the Unicode ‘201C’ and ‘201D’ in his find eypression. What if you replace both expressions into ‘0022’? It worked fine for me…
Martin
October 20th, 2009 at 1:25 am
Sorry Martin. It still cannot find match…
On the other hand, THIS code seems to find the symbols; (?<=”).*?(?=”)
BUT it cant change it to the ones I want.
Help me please!
Anita
July 12th, 2010 at 9:35 pm
I LOVE GREP…
Now, I’m working on a volleyball yearbook and I am facing a very challenging formatting problem.
I have this:
player 1a-player 1b [xx] vs player 2a-player 2b [xx] 2-0
player 1a-player 1b [xx] vs player 2a-player 2b [xx] 1-2
and so on. The xx in square brackets is the ranking, from 1 to 32. What I need is to apply a bold character style to the WINNING team; so, it’s some sort of conditional GREP, but I’m not sure at all if this could be accomplished. Any idea? It’s worth hours of my life…
May 7th, 2012 at 2:05 pm
I am looking for something a little different. I have a list that looks like this.
Here’s an example of a correct listing:
CATEGORY NAME 1
Company Name 1
Street Address 1
City, State, Zip 1
Company Name 2
Street Address 2
City, State, Zip 2
Company Name 3
Street Address 3
City, State, Zip 3
CATEGORY NAME 2
Company Name 1
Street Address 1
City, State, Zip 1
Company Name 2
Street Address 2
City, State, Zip 2
Company Name 3
Street Address 3
City, State, Zip 3
and this is how the problem listings showed up:
CATEGORY NAME 1
Company Name 1
Street Address 1
City, State, Zip 1
CATEGORY NAME 1
Company Name 2
Street Address 2
City, State, Zip 2
CATEGORY NAME 1
Company Name 3
Street Address 3
City, State, Zip 3
CATEGORY NAME 2
Company Name 1
Street Address 1
City, State, Zip 1
CATEGORY NAME 2
Company Name 2
Street Address 2
City, State, Zip 2
CATEGORY NAME 2
Company Name 3
Street Address 3
City, State, Zip 3
How do I remove the repeated CATEGORY NAMES after the first initial one?
May 7th, 2012 at 2:32 pm
I believe this is do-able. I’m working out the kinks of an expression that gets me partly there, but is omitting the entries between the first and last instances of the category. I think I can work that out. Will post here as soon as I figure out how.
May 8th, 2012 at 8:21 am
Thanks, this would be a big help since I believe you can do anything with the right grep that you can do with a similar plug in like IN-DATA. IN-DATA seems to be an overkill for a lot of simple things GREP can do and with the FINDBYLIST script, you can generate everything in one shot. GREP and Find and Change has come a long way.